Let’s be honest. In today’s digital landscape, “we value your privacy” can feel like an empty promise. Users are rightfully skeptical. Regulations like GDPR and CCPA have set the stage, but true innovation demands we go beyond compliance. We need to build software that architecturally respects privacy.
That’s where two powerful, and honestly, fascinating techniques come in: differential privacy and federated learning. Used separately, they’re strong. Combined? They can be transformative. This isn’t just theory—it’s the bedrock of next-gen apps in healthcare, finance, and beyond. Let’s dive in.
The Core Problem: Learning from Data Without Seeing It
Think of it this way. You want to understand traffic patterns in a city. The old way? Install cameras on every corner, stream all the video to a central server, and analyze it. It works, but it’s a privacy nightmare. The new way? Have each car report only anonymized, noisy snippets about its journey—no exact routes, no license plates—and learn the patterns from that. You get the insight without the intrusive surveillance.
That’s the essence of building privacy-preserving software. It’s a shift in mindset. The goal isn’t to collect and then protect, but to design systems where sensitive data simply never needs to be centralized in the first place.
Differential Privacy: The Science of “Plausible Deniability”
Okay, so what is it? In simple terms, differential privacy is a mathematical guarantee. It ensures that the output of an analysis (a statistic, a model) is essentially the same whether any single individual’s data is included in the dataset or not. You know, it gives that individual “plausible deniability.”
How does it work? By carefully adding calibrated randomness—noise—to the data or the query results. Not enough to wreck the overall accuracy, but enough to obscure any one person’s contribution. It’s like a choir: you can hear the overall song clearly, but picking out any single voice is impossible.
Implementing Differential Privacy: Key Levers
When you’re building, you’ll play with two main parameters:
- Epsilon (ε): The “privacy budget.” A lower epsilon means stronger privacy (more noise), but less accurate outputs. It’s a tightrope walk.
- Delta (δ): A tiny probability that the pure privacy guarantee might fail. You want this to be cryptographically small, like 1e-10.
Here’s a quick look at where you might apply it:
| Use Case | DP Application | Practical Consideration |
| Aggregate Analytics | Adding noise to counts or averages (e.g., “How many users clicked button X?”) | Managing the privacy budget over multiple queries is crucial. |
| Machine Learning | Adding noise during model training (DP-SGD algorithm) | Can increase the amount of training data needed for same accuracy. |
| Data Releases | Publishing a synthetic dataset that mirrors statistical properties | Great for sharing research data without exposing real individuals. |
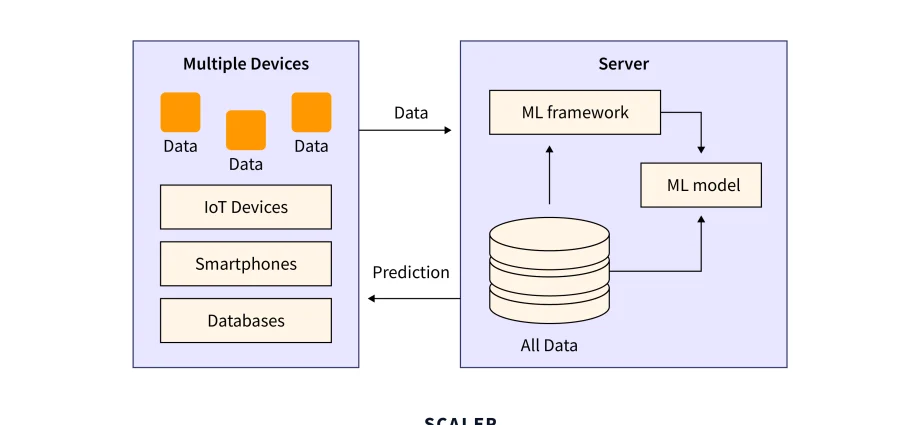
Federated Learning: Leave the Data Where It Is
Now, federated learning takes a completely different tack. Imagine training a model not by gathering all the data to one supercomputer, but by sending the model on a journey to the data. The model visits thousands of devices—phones, edge servers, hospital databases—learns a little on each one, and only the learned updates (not the raw data) are sent back to be aggregated.
The data stays put. It never leaves its source. This is a game-changer for building privacy-first applications on edge devices.
The Federated Learning Workflow, Simplified
- Server Initializes: A central server creates a global model.
- Broadcast: It sends this model to a selected cohort of devices.
- Local Training: Each device trains the model on its own local data.
- Update Transmission: Devices send only the model updates (gradients) back to the server.
- Secure Aggregation: The server combines these updates to improve the global model.
- Repeat: The cycle continues, iteratively improving the model.
The pain point here? Well, communication overhead is huge. And you have to assume most participants are “honest but curious”—they’ll follow the protocol but might try to infer others’ data from the updates. Which is where our two heroes join forces.
The Power Couple: Combining DP and FL for Robust Privacy
This is where the magic happens for software builders. Federated learning alone prevents raw data collection, but the model updates themselves can sometimes be reverse-engineered. A determined adversary might peek at them.
So, you add differential privacy into the federated learning loop. Before a device sends its model update to the server, it adds a dash of differential privacy noise to that update. Now, even if someone intercepts the update, they can’t reliably infer the original data it was trained on. You get a layered defense.
It’s like having a confidential meeting where not only are the minutes summarized (federated learning), but the summaries are also subtly paraphrased (differential privacy) to protect who said what.
Building It: Practical Steps and Real-World Snags
Alright, you’re sold on the concept. How do you actually start building privacy-preserving software with these tools? Here’s the deal.
First, audit your data flow. Map where sensitive data lives, moves, and is processed. The goal is to minimize central collection points from day one.
Next, choose your battlefield. Start with a non-critical model or statistic. Maybe it’s a next-word prediction keyboard or an app feature popularity dashboard. The learning curve is steep—tuning the noise, managing budgets, handling device dropouts in FL. You don’t want your first attempt to be your core revenue model.
Leverage frameworks. Thankfully, you don’t need to invent the math. Google’s TensorFlow Privacy and TensorFlow Federated are solid starting points. OpenMined’s PySyft is another. They abstract away the brutal complexity.
And be ready for trade-offs. The privacy-utility trade-off is real. Your model might be 2-5% less accurate, or take longer to train. You need to ask: Is that an acceptable cost for the trust we’re building? For many sectors today, the answer is a resounding yes.
The Road Ahead: More Than a Feature
Look, implementing differential privacy and federated learning isn’t just adding a feature. It’s a fundamental architectural shift. It signals to users that you respect the boundaries of their digital lives. It turns privacy from a legal checkbox into a selling point—a core component of your product’s integrity.
The tech is maturing fast. We’re seeing it in smartphone keyboards, healthcare research collaborations, and even in-car systems. The early challenges of efficiency and accuracy are being chipped away month by month.
Building this way is harder, sure. It requires more thought, more compute in some ways, and a willingness to accept good-enough answers instead of perfect ones. But in a world drowning in data breaches and distrust, that harder path might just be the only one worth taking. It builds not just software, but confidence.